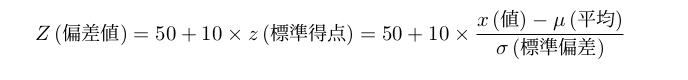・指定列に対して昇順
DB=> select * from テーブル名 order by 列名;
・数を数として並べ替え
DB=> select * from テーブル名 order by 列名::integer;
DB=> select * from テーブル名 order by cast( 列名 as integer );
・指定列に対して降順
DB=> select * from テーブル名 order by 列名 desc;
・列を複数指定
DB=> select * from テーブル名 order by 列名 desc, 列名;
列名、テーブル名を別名に変更
DB=> select 列名 as "別名" from テーブル名 as "別名";
※ AS は省略できる
Perl の場合
my $sql = "select count(*) as \"run\",";
$sql .= " count( chaku = 1 or null ) as \"1st\", .....";
列名を <!-- tmpl_var name="パラメータ名" --> のパラメータ名に変更して、
fetchrow_hashref, bind_colums + fetchrow_arrayref で取得
case
when 条件 then 結果
else 結果
end
DB=> select student as "名前", subject as "教科", score as "点数",
case
when score >= 70 then '合格'
when score < 70 then '不合格'
else null
end as "結果"
from テーブル名 where student = '田中';
氏名
教科
点数
結果
田中
国語
80
合格
田中
数学
65
不合格
田中
英語
90
合格
田中
理科
60
不合格
田中
社会
85
合格
検索条件
DB=> select * from テーブル名 where 条件式;
where 句で使用できる演算子
=, >, <, >=, <=, !=(<>), and, or, not, in, like, between 最小値 and 最大値 など
IS NULL, IS NOT NULL
・IS NULL(空である)
DB=> select * from テーブル名 where 列名 is null;
・IS NOT NULL(空でない)
DB=> select * from テーブル名 where 列名 is not null;
NULL 値の変換
DB=> select coalesce(列名, '空') from テーブル名;
IN, NOT IN, ALL
・IN(どれか)
DB=> select * from テーブル名 where 列名 in (1, 2, 3);
・NOT IN(以外)
DB=> select * from テーブル名 where 列名 not in (1, 2, 3);
・ALL(全て)
DB=> select * from テーブル名 where 列名 != all (array[1,2,3]);
副問い合わせ(サブクエリ)
最終レコードのデータを取得、()の中が先に処理される
DB=> select * from テーブル名 where no = ( select max(no) from テーブル名 );
あいまい検索
DB=> select * from テーブル名 where 列名 like '%文字列%';
'%文字列%' 含まれる
'%文字列' 終わりが一致
'文字列%' 始まりが一致
'文字列_文字列' _(アンダースコア)は、任意の一文字に一致
※ _(アンダースコア)を文字として扱いたい場合は、\ を付けてエスケープする
Perl プレースフォルダー使用時
my $sql = " ..... where 列名 like ?";
$sth->execute( "文字列%" ); % はパラメータ(値)に含める
正規表現
DB=> select * from テーブル名 where 列名 ~ 'パターン';
集計関数
・行数をカウント
DB=> select count(列名) from テーブル名;
・条件にマッチする行数をカウント
DB=> select count( 条件 or null ) from テーブル名;
DB=> select count( chaku = 1 or null ) as "一着回数" from テーブル名;
※ NULL 値はカウントされない、NULL 値を含める場合
DB=> select count( 条件 or null or 列名 is null ) from テーブル名;
DB=> select count( chaku >= 4 or null or chaku is null ) as "着外回数" from テーブル名;
・最大値
DB=> select max(集計する列名) from テーブル名;
・最小値
DB=> select min(集計する列名) from テーブル名;
・合計値
DB=> select sum(集計する列名) from テーブル名;
・条件にマッチする合計値
DB=> select sum( case when 条件 then 集計する列名 else null end ) from テーブル名;
・平均値
DB=> select avg(集計する列名) from テーブル名;
・条件にマッチする平均値
DB=> select avg( case when 条件 then 集計する列名 else null end ) from テーブル名;
DB=> select avg( case when chaku <= 2 then runtime else null end )
as "平均連対タイム" from テーブル名;
・合計値の平均値
DB=> select avg( A.score_sum )
from ( select sum( score ) as score_sum from test_tbl group by student ) as A;
・標準偏差
DB=> select stddev(集計する列名) from テーブル名;
縦持ちデータを横持ちに変換
DB=> select race_id,
min( case when chaku = 1 then jockey else null end ) as "勝利騎手",
min( case when chaku = 1 then umaban else null end ) as "一着",
min( case when chaku = 2 then umaban else null end ) as "二着",
min( case when chaku = 3 then umaban else null end ) as "三着",
min( case when chaku = 1 then leg else null end ) as "勝利脚質"
from テーブル名 group by race_id;
having は where と同じ条件、where が行に適用されるのに対し、having はグループに適用される。
DB=> select 列名, count(*) from テーブル名 group by 列名 having グループに適用される条件;
・例1
DB=> select student as "名前", sum( score ) as "合計点"
from テーブル名 group by student;
名前
合計点
田中
380
鈴木
385
佐藤
380
高橋
335
山本
345
・例2
DB=> select round( avg( A.score_sum ), 1 ) as "合計点の平均"
from ( select sum( score ) as score_sum from test_tbl group by student ) as A;
合計点の平均
365.0
・例3
DB=> select student as "名前", sum( score ) as "合計点" from テーブル名
group by student having sum( score ) >= 350;
名前
合計点
田中
380
鈴木
385
佐藤
380
・例4
DB=> select student as "名前", sum( score ) as "合計点",
case
when sum( score ) >= 350 then '合格'
when sum( score ) < 350 then '不合格'
else null
end as "結果"
from テーブル名 group by student;
名前
合計点
結果
田中
380
合格
鈴木
385
合格
佐藤
380
合格
高橋
335
不合格
山本
345
不合格
偏差値
・プロシージャ
作成 交換 プロシージャ 引数
DB=> CREATE OR REPLACE PROCEDURE hensachi_proc(name varchar(4))
AS $$
DECLARE
kamoku_list varchar(4)[]; kamoku varchar(4);
avg1 numeric(3,1); stddev1 numeric(3,1); score1 int;
hensachi1 numeric(3,1);
avg5 numeric(4,1); stddev5 numeric(3,1); score5 int;
hensachi5 numeric(3,1);
BEGIN
kamoku_list := array['国語', '数学', '英語', '理科', '社会'];
FOREACH kamoku IN ARRAY kamoku_list
LOOP
RAISE INFO '%', kamoku;
select into avg1 round( avg( score ), 1 ) from test_tbl where subject = kamoku;
select into stddev1 round( stddev( score ), 1 ) from test_tbl where subject = kamoku;
select into score1 score from test_tbl where student = name and subject = kamoku;
select into hensachi1 round( 50 + 10 * ( (score1 - avg1) / stddev1 ), 1 );
RAISE NOTICE '平均 %, 標準偏差 %, % 点数 % 偏差値 %',
avg1, stddev1, name, score1, hensachi1;
END LOOP;
RAISE INFO '5科目';
select into avg5 round( avg(A.score_sum), 1 )
from (select sum( score ) as score_sum from test_tbl group by student) as A;
select into stddev5 round( stddev(B.score_sum), 1 )
from (select sum( score ) as score_sum from test_tbl group by student) as B;
select into score5 sum( score ) from test_tbl where student = name group by student;
select into hensachi5 round( 50 + 10 * ( (score5 - avg5) / stddev5 ), 1 );
RAISE NOTICE '平均 %, 標準偏差 %, % 合計 % 偏差値 %',
avg5, stddev5, name, score5, hensachi5;
END;
$$
LANGUAGE plpgsql;
※ RAISE INFO '%', 変数名; # 変数の中身を表示(% に変数の値がセットされる)